Text | Silicon Valley 101
Sora, OpenAI’s AI-generated video model, once released on February 15th, 2024, attracted global attention. The author of the AI video paper in Silicon Valley (not Sora) commented: quite good, there is no doubt about it. No.1
What’s good about Sora? What are the development challenges of generative AI video? Is the video model of OpenAI necessarily the right route? Has the so-called "world model" reached a consensus? This video,Through interviews with front-line AI practitioners in Silicon Valley, we have an in-depth talk about the development history of different factions of the generative AI video model, everyone’s disputes and future routes.
We actually wanted to do this topic last year, because when chatting with many people, including VC investors, we found that the difference between AI video model and ChatGPT, a big language model, was not very clear. But why didn’t you do it? Because at the end of last year, the best thing in the market was the function of Gen1 and Gen2, which are owned by runway, to generate video and text to generate video, but the effect we generated … is a bit complicated.
For example, in a video generated by runway, the prompt prompt is "super mario walking in a desert", and the resulting video is like this:
What do you think? Like Mario jumping on the moon. Whether it is gravity or friction, physics seems to suddenly disappear in this video.
Then we tried another cue, "A group of people walking down a street at night with umbrellas on the windows of stores." (A group of people are walking under the umbrella of the window eaves of a shop on a rainy night). This cue was also tried by an investor Garrio Harrison, and the resulting video was like this:
Look at this umbrella floating in the air, isn’t it weird … but this is the runway that represented the most advanced technology last year. After that, Pika Labs, founded by Chinese founder Demi Guo, became a hit for a while. It is considered to be slightly better than runway, but it is still limited by the length display of 3-4 seconds, and the generated video still has defects such as video understanding logic and hand composition.
So, before OpenAI released the Sora model,The generative AI video model has not attracted global attention like ChatGPT, Midjourney and other chat and text-based applications, largely because the technical difficulty of generating video is very high.Video is a two-dimensional space+time, from static to dynamic, from plane to plane in different time segments, which requires not only powerful algorithms and computing power, but also a series of complex problems such as consistency, coherence, physical rationality and logical rationality.
Therefore, the topic of generative video model has always been on the list of topics of Silicon Valley 101, but it has been delayed. We want to do this topic again when there is a major breakthrough in generative AI video model. Unexpectedly, this moment is coming so soon.
Sora’s display is undoubtedly the hanging of the previous runway and pika labs.
First of all, one of the biggest breakthroughs,Very intuitive is:The length of that generate video is greatly prolonged.Previously, runway and pika could only generate 3-4 seconds of video, which was too short, so the AI video works that could be circled before were only some fast-paced movie trailers, because other uses that needed longer materials could not be met at all.
On runway and pika, if you need a longer video, you need to constantly remind yourself of the duration of the superimposed video, but Jacob, our post-video editor, found that there would be a big problem.
Jacob, Silicon Valley 101 video post-editor:
The pain point is that when you continue to extend it later, the video behind it will be deformed, which will lead to inconsistency between the video images before and after, and then this material will not be used.
Sora’s latest paper and demo show that a video scene of about 1 minute can be generated directly according to the prompt words. At the same time, Sora will take into account the transformation of character scenes and the consistency of themes in the video. This made our editor excited after watching it.
Jacob, Silicon Valley 101 video post-editor:
(Sora) One of the videos shows a girl walking on the street in Tokyo … For me, this is very powerful. Therefore, even in the dynamic motion of the video, with the movement and rotation of the space, the people and objects appearing in Sora video will keep the consistent movement of the scene.
Third, Sora can accept videos, images or prompts as input.The model will generate video according to the user’s input,For example, a burst cloud in the demo was released. This means that Sora model can make animation based on static images, so as to expand the video forward or backward in time.
Fourthly, Sora can read and sample different widescreen or vertical videos, and can also output videos of different sizes according to the same video, and keep the style stable.For example, a sample of this little turtle. This is actually very helpful for our later video. Now, 1920*1080p horizontal video such as Youtube and bilibili, we need to re-cut it into vertical 1080*1920 video to adapt to short video platforms such as Tiktok and Tiktok, but it is conceivable that we may be able to convert it through Sora one-click AI, which is also a function I am looking forward to.
Fifth, long-distance coherence and time coherence are stronger.Previously, it was very difficult for AI to generate video, that is, the coherence of time, but Sora can remember the people and objects in the video well, even if it is temporarily blocked or moved out of the picture, it can keep the video coherent according to physical logic when it reappears later. For example, the video of this puppy released by Sora, when people walk past it, the picture is completely blocked, and when it appears again, it can naturally continue to move and keep the continuity of time and objects.
Sixth, Sora model can simply simulate the action of the world state.For example, the painter leaves new strokes on the canvas, which will persist over time, or a person will leave bite marks on the hamburger when eating it. There is an optimistic interpretation that this means that the model has a certain general knowledge, can "understand" the physical world in motion, and can also predict what will happen next in the picture.
Therefore, the shocking updates brought by the above Sora models have greatly improved the expectations and excitement of the outside world for the development of generative AI video. Although Sora will also have some logical errors, such as the cat having three claws, the street view having unconventional obstacles, and the person’s direction on the treadmill being reversed, etc., obviously, compared with the previous generated video, runway, pika or Google’s videopoet, Sora is an absolute leader, andMore importantly, OpenAI seems to want to prove through Sora that the "miracle-making" method of calculating the parameters of the power reactor can also be applied to the generated video, and through the integration of the diffusion model and the large language model, such a new model route will form the basis of the so-called "world model"And these views have also caused great controversy and discussion in the AI session.
Next, we will try to review the technical development of the generative AI model, and try to analyze how Sora’s model works. Is it the so-called "world model"?
In the early stage of AI video generation, it mainly relies on two models: GAN (Generative Countermeasure Network) and VAE (Variational Self-Encoder). However, the video content generated by these two methods is relatively limited, relatively single and static, and the resolution is often not good, so it is completely impossible to be commercialized. So we won’t talk about these two models first.
After that,Video generated by AI has evolved into two technical routes, one is the diffusion model specially used in the video field, and the other is the Transformer model.Let’s talk about the route of the diffusion model first, and the companies that ran out are Runway and Pika Labs.
Diffusion Model is diffusion model in English. Many people don’t know that the original model of the most important open source model, Stable Diffusion, was released by Runway and the team of Munich University, and Stable Diffusion itself is the underlying technical foundation behind Runway’s core products-video editors Gen-1 and Gen-2.
Gen-1 model was released in February 2023, which allows people to change the visual style of the original video by inputting text or images, for example, turning the real street scene shot by mobile phones into the cyber world. In June, runway released Gen-2, which further enabled users to directly generate text prompts as videos.
The principle of diffusion model,As soon as you hear the name "diffusion model", you can get a little:Image or video is generated by gradual diffusion.In order to better explain the principle of the model to everyone, we invited Dr. Zhang Songyang, one of the authors of the previous Meta Make-A-Video model and currently engaged in video generation model in Amazon AGI team, to give us an explanation.
Dr. Zhang Sean Song, one of the authors of the Meta Make-A-Video model, and an applied scientist of Amazon AGI team;
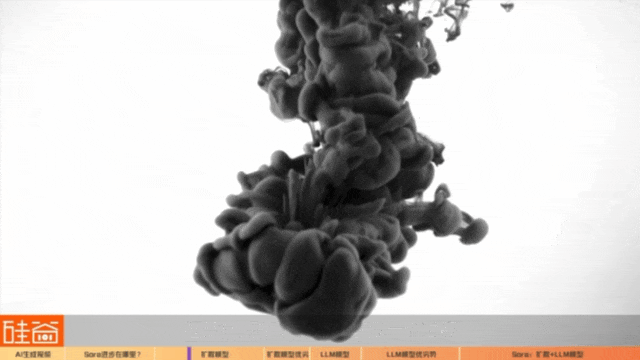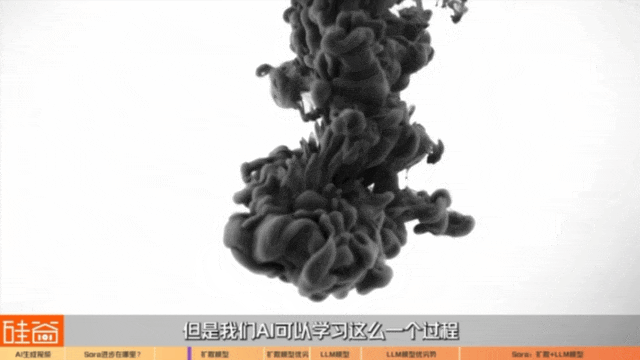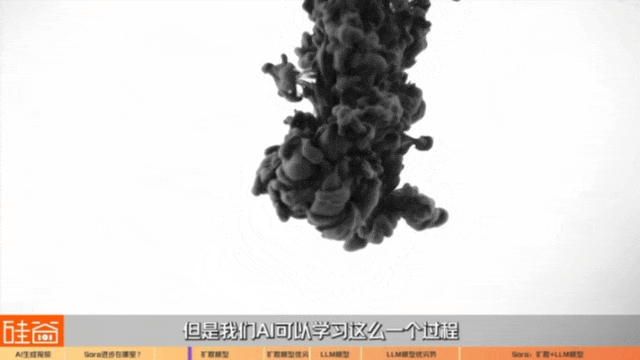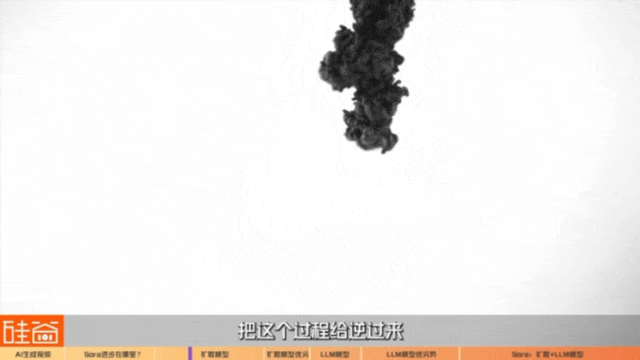
The reason why the name diffusion was used in this paper at the beginning stems from a physical phenomenon, that is to say, if we drop ink into a glass of water, it will disperse, and this thing is called diffusion. This process itself is physically irreversible, but we AI can learn such a process and reverse it. It is a picture by analogy with a picture. It keeps adding noise, and then it will become an effect similar to mosaic. It is a picture with pure noise. Then we learn how to turn this noise into an original picture.
If we train such a model and complete it directly in one step, it may be difficult. It is divided into many steps, for example, I divide it into 1000 steps. For example, if I add a little noise, it can restore what it looks like after removing the noise, and then the noise is added.More often, how can I use this model to predict noise? That is, it is divided into many steps, and then it gradually removes the noise, and it iteratively removes the noise slowly. For example, it turns out that water and ink have been completely mixed together. How can you predict it and how can it change back to the previous drop of ink step by step? Is that it is an inverse process of diffusion.
Dr. Zhang Sean Song explained it vividly.The core idea of diffusion model is to gradually generate realistic images or videos by constantly introducing randomness into the original noise. Now this process is divided into four steps:
1) initialization:The diffusion model begins with a random noisy image or video frame as the initial input.
2) diffusion process (also called forward process):The goal of the diffusion process is to make the picture unclear and finally become complete noise.
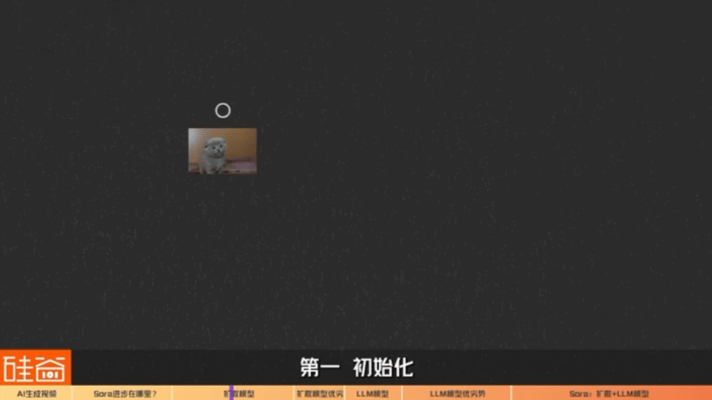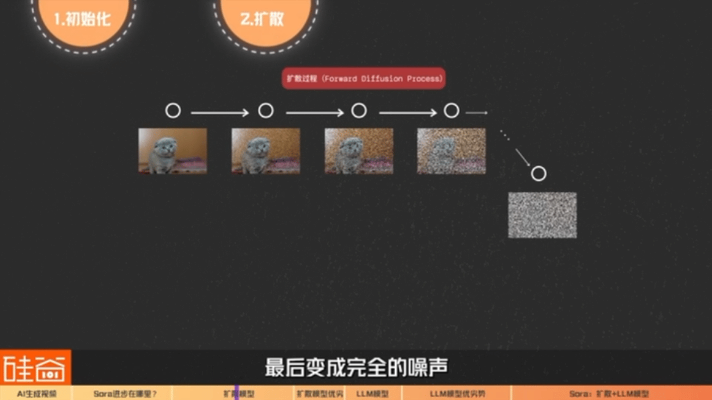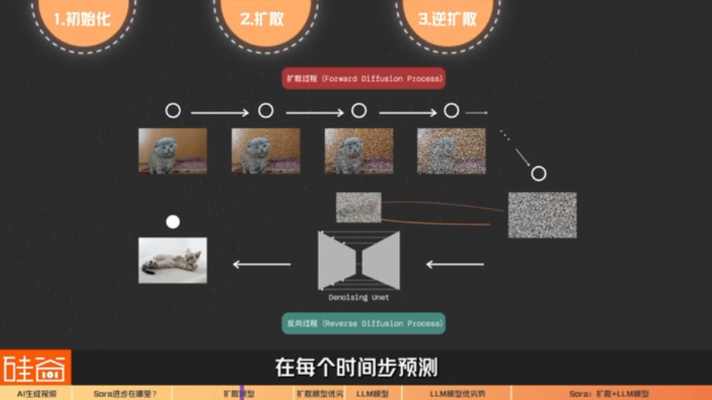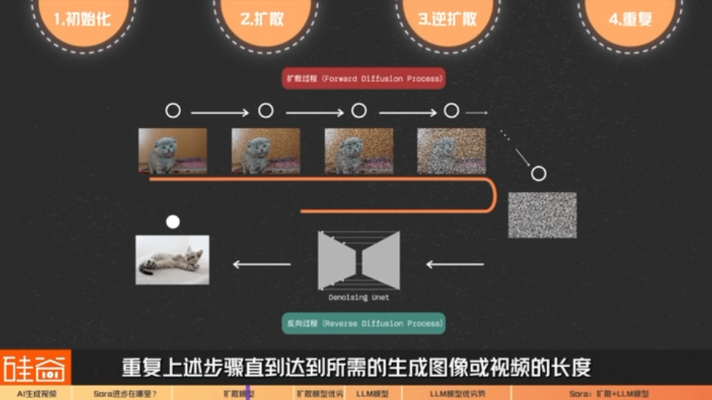
3) reverse process (also known as backward diffusion):At this time, we will introduce the "neural network", such as the UNet structure based on the convolutional neural network (CNN), and predict the "added noise to achieve the blurred image of the current frame" at each time step, so as to generate the next frame image by removing this noise, so as to form the realistic content of the image.
4) Repeat the steps: repeat the above steps until the required length of the generated image or video is reached.
The above is the generation mode of video to video or picture to video, and it is also the basic technical operation mode of runway Gen1. If you want to input prompt words to achieve text to video, then you need to add a few more steps.
For example, let’s take the Imagen model released by Google in mid-2022 as an example: our prompt isA boy is riding on the Rocket, a boy riding a rocket. This prompt will be converted into tokens and passed to the encoder text encoder. Google IMAGEN model then uses T5-XXL LLM encoder to encode the input text as embeddings. These embedments represent our text prompts, but they are coded in a way that the machine can understand.
These "embedded texts" will then be passed to an image generator, which will generate low-resolution images with 64×64 resolution. After that, the IMAGEN model uses the super-resolution diffusion model to upgrade the image from 64×64 to 256×256, and then adds a layer of super-resolution diffusion model, and finally generates a 1024×1024 high-quality image closely combined with our text prompts.
To sum up briefly, in this process, the diffusion model starts from the random noise image, and in the denoising process, the coded text is used to generate high-quality images.
And why is it so difficult to generate video than to generate pictures?
Dr. Zhang Sean Song, one of the authors of the Meta Make-A-Video model, and an applied scientist of Amazon AGI team;
Its principle is actually the same, but the only difference is that there is an additional timeline. It’s the picture we just talked about. It’s a picture.It’s 2D. It’s height and width. Then video it has an extra timeline, it is a 3D, it is the height, width and time. Then in the process of learning the inverse process of diffusion, it is equivalent to a 2D inverse process before, and now it becomes a 3D inverse process, which is such a difference.
So the problems in the picture, such as these generated faces, are they real? Then if we have such a problem in the picture, so will our video. For the video, it has some unique problems, such as whether the main body of this picture is consistent as you said just now. I think at present, for things like scenery, the effect is actually ok. Then, if people are involved, because these requirements of people may be more detailed, it will be more difficult for people. This is a problem. Then there is a current difficulty, which I think is also a direction that everyone is working hard on, that is, how to make the video longer. Because at present, only generating videos of 2 seconds, 3 seconds and 4 seconds is far from satisfying the current application scenarios.
Compared with previous models such as GAN, the diffusion model has three main advantages:
First, stability:The training process is usually more stable, and it is not easy to fall into problems such as pattern collapse or pattern collapse.
Second, the generated image quality: Diffusion model can generate high-quality images or videos, especially in the case of sufficient training, and the generated results are usually more realistic.
Third, no specific architecture is required: The diffusion model does not depend on the specific network structure, and has good compatibility. Many different types of neural networks can be used.
howeverThe diffusion model also has two main shortcomings,Including:
First, the training cost is high:Compared with some other generation models, the training of diffusion model may be more expensive, because it needs to learn to dry under different noise levels, and it takes longer to train.
Secondly, it takes more time to generate.Because it needs to be dried step by step to generate images or videos, instead of generating the whole sample at one time.
Dr. Zhang Sean Song, one of the authors of the Meta Make-A-Video model, and an applied scientist of Amazon AGI team;
One of the most important reasons why we can’t actually grow videos now is that our video memory is limited. Generating a picture may occupy a part of the main memory, and then if you generate 16 pictures, you may almost fill this main memory. When you need to generate more pictures, you have to find a way to get there, considering the information that has been generated before, and then predicting what kind of information to generate later. First of all, it puts forward a higher requirement on the model. Of course, the computational power is also a problem, that is, after many years of acquisition, our memory will be very large, and maybe we won’t have such a problem. It is also possible, but for now, we need a better algorithm, but if we have better hardware, this problem may not exist.
Therefore, it is doomed that the current video diffusion model itself may not be the best algorithm, although representative companies such as runway and PikaLabs have been optimizing the algorithm.
Next, let’s talk about another faction:Video technology route generated by large language model based on Transformer architecture.
Finally, at the end of December, 2023, Google released a generative AI video model, VideoPoet, based on the big language model, which was regarded as another solution and way out besides the diffusion model in the field of generating video at that time. What is the principle?How does the big language model generate video?
The generation of video by large language model is realized by understanding the temporal and spatial relationship of video content. Google’s VideoPoet is an example of using a large language model to generate video. At this time, let’s invite Dr. Zhang Sean Song, a generative AI scientist, to give us a vivid explanation.
Dr. Zhang Sean Song, one of the authors of the Meta Make-A-Video model, and an applied scientist of Amazon AGI team;
Then the big language model is completely different in principle. It is used on the text at first, that is, I predict what the next word is, for example, "I love telling the truth", then the last "I love telling the truth", and then what is the last word? Guess what word it is? Then maybe the more words you give in front of these words, the easier it is for you to guess the back. But if you give fewer words, you may have more room to play. It is such a process.
Then this idea is brought to the video, that is, we can learn the vocabulary of a picture, or the vocabulary of the video. That is to say, we can cut the picture horizontally, for example, 16 times horizontally and 16 times vertically, and then treat each small square and grid as a word, and then input it into this big language model for them to learn. For example, you have a good big language model before, and then you learn how to interact with these words in the big language model and the words in these texts or videos, and what kind of association is there between them? You learn some of this stuff, and then in this way, we can use these large language models to do some video tasks or some text tasks.
Simply put, the Videopoet based on the big language model works like this:
1) Input and understanding:First, Videopoet receives text, sound, picture, depth map, optical flow map, or video to be edited as input.
2) Video and sound coding:Because the text is a discrete form, the large language model naturally requires that the input and output must be discrete features. However, video and sound are continuous quantities. In order to make the big language model also use pictures, videos or sounds as input and output, here Videopoet encodes video and sound into discrete token. In deep learning, token is a very important concept, which refers to a group of symbols or identifiers used to represent a specific element in a group of data or information. In the example of Videopoet, it can be understood as the words of video and the words of sound.
3) Model training and content generation:With these Token words, we can train a Transformer to learn the tokens of predicting videos one by one according to the input given by users, just like learning text tokens, and the model will begin to generate content. For video generation, this means that the model needs to create a coherent frame sequence, which is not only visually logical, but also continuous in time.
4) Optimization and fine-tuning:The generated video may need further optimization and fine-tuning to ensure quality and consistency. This may include adjusting colors, lighting and transitions between frames. VideoPoet uses deep learning technology to optimize the generated videos, ensuring that they are not only in line with the text description, but also visually attractive.
5) Output: Finally, the generated video will be output for the end users to watch.
However, the route of generating video by large language model also has advantages and disadvantages.
Let’s talk about it firstAdvantages:
1) High understanding: The large language model based on Transformer architecture can process and understand a large amount of data, including complex text and image information. This makes the model have the ability of cross-modal understanding and generation, and can well learn the ability of correlation between different modes of text and picture video. This enables them to generate more accurate and relevant output when converting text descriptions into video content.
2) processing long sequence data: Because of the self-attention mechanism, the Transformer model is particularly good at processing long sequence data, which is especially important for video generation, because video is essentially a visual representation of long sequences.
3) Scalability of 3)Transformer:Generally speaking, the larger the model, the stronger the fitting ability. However, when the model is large enough, the gain of convolutional neural network performance will slow down or even stop due to the increase of the model, while Transformer can continue to grow. Transformer has proved this point in the big language model, and now it is gradually emerging in the field of image and video generation.
Let’s talk about it againDisadvantages:
1) Resource-intensive:Using large language model to generate video, especially high-quality video, requires a lot of computing resources, because the route of using large language model is to encode video into token, which is often much larger than the vocabulary of a sentence or even a paragraph. At the same time, if you predict one by one, it will cost a lot of time. In other words, this may make the training and reasoning process of Transformer model expensive and time-consuming.
Dr. Zhang Sean Song, one of the authors of the Meta Make-A-Video model, and an applied scientist of Amazon AGI team;
There is a problem that I think is quite essential, that is, transformer is not fast enough. This is a very essential problem, because transformer predicts the diffusion model block by block, and the diffusion model comes out directly, so transformer will definitely be slow.
Chen Qian, video manager of Silicon Valley 101:
It’s too slow. Is there a concrete data? Just how much slower?
Dr. Zhang Sean Song, one of the authors of the Meta Make-A-Video model, and an applied scientist of Amazon AGI team;
For example, if I draw a picture directly, the difference, for example, if a picture is 1, it also needs some iterative processes. Then, for example, I use four steps, which is four steps to generate, and we are four. If we do well at present, I think the effect of four steps is still good. Then but if you use transformer, for example, if you draw a square of 16*16, that’s 16*16, that’s 256, that’s the speed.
4 is equivalent to I did denoising iteration four times. Then transformer, it is equivalent to me to predict a picture, for example, 16*16, I predict 256 words. Their dimensions are definitely different, but you can see their complexity. It is the diffusion model, and its complexity is a constant set. But the complexity of transformer, which is actually a width x height, will be different. Therefore, from the perspective of complexity, the diffusion model is definitely better. Then specifically, I think this thing may be that the bigger the picture is, the higher the resolution is, and the bigger the problem of transformer may be.
Other problems with the Transformer model include:
2) Quality fluctuation:Although the Transformer model can generate creative video content, the output quality may be unstable, especially for complex or insufficiently trained models.
3) Data dependency:The performance of Transformer model depends largely on the quality and diversity of training data. If the training data is limited or biased, the generated video may not accurately reflect the input intention or be limited in diversity.
4) Understanding and logical restrictions:Although the Transformer model has made progress in understanding the text and image content, it may still be difficult for them to fully grasp the complex human emotions, humor or subtle social and cultural signals, which may affect the relevance and attractiveness of the generated video.
5) Ethics and prejudice: Automatic video generation technology may inadvertently copy or amplify the bias in training data, leading to ethical problems.
But when it comes to the fifth point, I suddenly remembered a recent news that no matter who you type in Google’s multimodal model Gemini, people of color come out, including the founding father of the United States, the black female version of the Pope, the Vikings are also colored, and the generated Elon Musk is also black.
The reason behind this may be that in order to correct the prejudice in the Transformer architecture, Google added the adjustment instructions of AI ethics and security, and the result was overdone, resulting in this big oolong. However, this happened after OpenAI released Sora, which really made Google ridiculed by the group.
However, the insiders also pointed out that the above five problems are not unique to the transformer architecture. At present, any generation model may have these problems, but the advantages and disadvantages of different models are slightly different in different directions.
So, to sum up here, there are some unsatisfactory places in the video generated by diffusion model and Transformer model. So, as the most cutting-edge company in technology, how do they do it? Well, maybe you guessed that these two models have their own advantages. If I combine them, will it be 1+1>2? So,Sora is the combination of diffusion model and Transformer model.
To tell the truth, the details of Sora are still unknown to the outside world, and it is not open to the public now. Even waitinglit is not open. Only a few people from the industry and design circles are invited to use it, and the videos produced are also made public online. For technology, it is more based on the guessing and analysis of the effect video given by OpenAI. OpenAI gave a vague technical explanation on the day Sora was released, but many technical details were missing.
butLet’s start with this technical analysis published by Sora.Let’s take a look at how OpenAI’s diffusion+big language model technology route works.
Sora made it very clear at the beginning:OpenAI "jointly trains text-conditional diffusion models" on videos and images with variable duration, resolution and aspect ratio. At the same time, the Transformer architecture is used to operate the spacetime patches of video and image potential codes.
So,The steps of Sora model generation include:
Step 1: Video compression network
In the video generation technology based on the big language model, we mentioned coding the video into discrete token, and Sora adopted the same idea here.Video is a three-dimensional input (two-dimensional space+one-dimensional time), where the video is divided into small token in three-dimensional space, which is called "spacetime patches" by OpenAI.
Step 2: Text Understanding
Because Sora has the blessing of the OpenAI model DALLE3, many videos without text annotation can be automatically labeled and used for the training of video generation. At the same time, thanks to the GPT, the user’s input can be expanded into a more detailed description, so that the generated video can be more suitable for the user’s input, and the transformer framework can help Sora model learn and extract features more effectively, obtain and understand a lot of detailed information, and enhance the generalization ability of the model to unseen data.
For example, if you type "a cartoon kangaroo is dancing disco", GPT will help Lenovo to say that it is necessary to wear a pair of sunglasses, a flowered shirt and a bunch of animals jumping together in the disco to give full play to Lenovo’s ability to explain the input prompt. Therefore, how well Sora can be generated will be determined by the rich explanations and details that GPT can develop. The GPT model is OpenAI’s own. Unlike other AI video startup companies, which need to call the GPT model, the efficiency and depth of the GPT architecture that OpenAI gives Sora are definitely the highest, which may be why Sora will do better in semantic understanding.
Step 3: Diffusion Transformer imaging.
Sora adopts the combination of Diffusion and Transformer.
Previously, we mentioned that Transformer has good scalability in video generation technology based on large language model. This means that the structure of Transformer will get better and better with the increase of the model. This feature is not available in all models. For example, when the model is large enough, the gain of convolutional neural network performance will slow down or even stop due to the increase of the model, while Transformer can continue to grow.
Many people will notice that Sora shows a stable ability in maintaining the stability, consistency, picture rotation, etc. of the picture objects, far exceeding the video models presented by runway, Pika, Stable Video and so on based on the Diffusion model.
I still remember that when we talked about the diffusion model, we also said: The challenge of video generation lies in the stability and consistency of the generated objects. This is because, although Diffusion is the mainstream of video generation technology, the previous work has been limited to the structure based on convolutional neural network, and it has not played its full potential. Sora skillfully combines the advantages of both Diffusion and Transformer, which makes the video generation technology get a greater improvement.
Furthermore, the video continuity generated by Sora may be obtained through the Transformer Self- Attention mechanism. Sora can discretize the time, and then understand the relationship between the time lines through the self-attention mechanism. The principle of self-attention mechanism is that each time point is related to all other time points, which is not available in the Diffusion Model.
At present, there are some speculations. In the third step of the diffusion model we mentioned earlier, Sora chose to replace the U-Net architecture with the Transformer architecture. This allows the Diffusion model, as a painter, to find a more appropriate part in OpenAI’s massive database according to the possibility probability corresponding to the keyword eigenvalues in the process of eliminating noise when starting to reverse diffusion and painting.
When I interviewed another AI practitioner, he used another vivid example to explain the difference here. He said: "The diffusion model predicts noise. Subtract the predicted noise from the picture at a certain time point, and you get the most original picture without noise, which is the final generated picture. It’s more like sculpture here. As Michelangelo said, he only removed the parts that should not exist in the stone according to God’s will, and finally he created great sculptures from it. Transformer, through the self-attention mechanism, understands the connection between time lines and makes this sculpture come down from the stone pedestal."Isn’t it pretty image?
Finally, Sora’s Transformer+Diffusion Model will patch the time and space to generate pictures, and then the pictures will be spliced into video sequences, and a Sora video will be generated.
Honestly,The methodology of Transformer plus diffusion model is not original by OpenAI.Before OpenAI released Sora, when we interviewed Dr. Zhang Sean Song in January this year, he mentioned that the way of adding diffusion model to Transformer has been widely studied in the industry.
Dr. Zhang Sean Song, one of the authors of the Meta Make-A-Video model, and an applied scientist of Amazon AGI team;
At present, we can see that some models of transformer are combined with diffusion, and then the effect may not be bad, or even some of them in the paper may be better. So I’m not sure how the model will develop in the future. I think it may be a way to combine the two. It’s like transformer, for example, it predictsThe next video has the natural advantage that it can predict what will become. Although the quality of diffusion is high, many practices of diffusion still generate a fixed number of frames. How to combine the two things is a process that will be studied later.
Therefore, this also explains why OpenAI wants to release Sora now. In fact, in the forum of OpenAI, Sora clarified that,Sora is not a mature product now, so it is not a released product, nor is it public, and there is no waiting list and no expected release date.
Some analysts outside believe that Sora is still immature, and the computing power of OpenAI may not be able to withstand the disclosure of Sora. At the same time, there are also false news security and moral problems after the disclosure, so Sora may not be officially released soon, but because transformer plus diffusion has become the direction of general attempts in the industry, at this time, OpenAI needs to demonstrate Sora’s ability to regain its leading position in the field of generative AI video with increasingly fierce competition.
With the verification of OpenAI, we can basically be sure that,The direction of AI video generation will shift to this new technology combination.OpenAI also clearly pointed out in the published technical article.The huge amount of parameters on ChatGPT, the way of "making great efforts to make miracles", has been proved in AI video generation.
OpenAI said in the article, "We found that the video model showed many interesting emerging functions during large-scale training. These functions enable Sora to simulate some aspects of people, animals and the environment in the real world.
This shows that Sora and GPT3 have the same emergence, which means that, like GPT language model, AI video needs more parameters, more GPU computing power and more capital investment.
Scaling is still the trick of generative AI at present, and this may also mean that generative AI video may eventually become a game of big companies.
Dr. Zhang Sean Song, one of the authors of the Meta Make-A-Video model, and an applied scientist of Amazon AGI team;
I think it may be more intuitive to be equivalent to you. For example, if you save a video, it may be tens of GB, and then it may be 1000 times larger in the big language model, and it will be TB, which is something like this, but I think you should be able to see such a trend, that is, although the parameter amount of the video is only at billion level now.
But like their previous stable diffusion model in the picture, they later produced a stable diffusion XL, and they also enlarged the model, and then brought some better effects, not to say better effects, that is, they could make a more realistic picture, and then the effect would be more obvious. I think this is a trend, that is, the number of parameters will definitely increase in the future, but how much gain it will bring depends on the structure of your current model, your data volume and what your data is like.
The above is our very preliminary analysis of Sora, and once again, because many technical details of Sora have not been made public, many of our analysis is also a guess from an external perspective. If there is any inaccuracy, please correct it, correct it and discuss it.